Object detection is a computer vision technique for locating instances of objects in images or videos. Object detection algorithms typically leverage machine learning or deep learning to produce meaningful results. When humans look at images or video, we can recognize and locate objects of interest within a matter of moments. The goal of object detection is to replicate this intelligence using a computer.
Addition: Due to a device limitation, Jetson Xavier does not currently support the pyrealsense2 library, so we are splitting the working node into two nodes: the Object recognition node running on Jetson Xavier and the Estimate coordinate node running on the Nuc so that the system able to continue working.
OpenCV (Open Source Computer Vision Library) is an open source computer vision and machine learning software library. OpenCV was built to provide a common infrastructure for computer vision applications and to accelerate the use of machine perception in the commercial products. Being an Apache 2 licensed product, OpenCV makes it easy for businesses to utilize and modify the code.
https://opencv.org/about/
You Only Look Once (YOLO) is one of the most popular model architectures and object detection algorithms. It uses one of the best neural network architectures to produce high accuracy and overall processing speed, which is the main reason for its popularity. If we search Google for object detection algorithms, the first result will be related to the YOLO model.
YOLO algorithm aims to predict a class of an object and the bounding box that defines the object location on the input image. It recognizes each bounding box using four numbers:
Center of the bounding box (b_x, b_y)
Width of the box (b_w)
Height of the box (b_h)
In addition to that, YOLO predicts the corresponding number c for the predicted class as well as the probability of the prediction (P_c)
In the Object Recognition node, we use YOLOv5 to detect objects, which results in a frame of the image containing the bounding box and a data frame of the detected object.
An HSV color model is the most accurate color model as long as the way humans perceive colors. How humans perceive colors is not like how RGB or CMYK make colors. They are just primary colors fused to create the spectrum.
This is the reason why we use the HSV color model for color detection.
The H stands for Hue, S stands for Saturation, and the V stands for value.
Hue: Hue tells the angle to look at the cylindrical disk. The hue represents the color. The hue value ranges from o to 360 degrees.
Saturation: The saturation value tells us how much quantity of respective color must be added. A 100% saturation means that complete pure color is added, while a 0% saturation means no color is added, resulting in grayscale.
Value: The value represents the brightness concerning the saturation of the color. The value 0 represents total black darkness, while the value 100 will mean a full brightness and depend on the saturation.
Since the image frame we received is based on the BGR color model, we need to convert the image frame to the HSV color model, which can be converted using the OpenCV library.
Then we can use the HSV color model to create the conditions for detecting different colors in the Object recognition node.
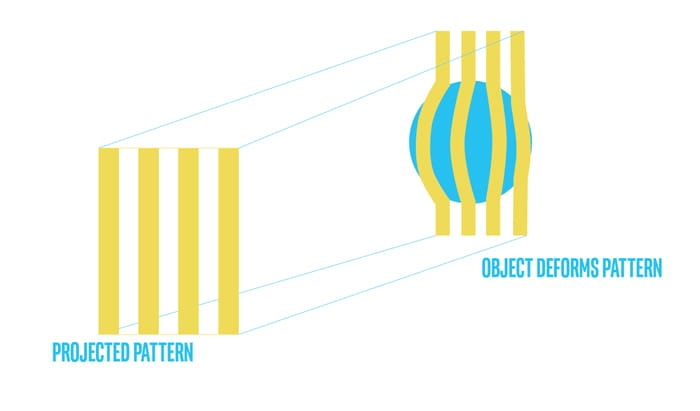
Structured light and coded Light depth cameras are not identical but similar technologies. They rely on projecting light (usually infrared light) from some kind of emitter onto the scene. The projected light is patterned, either visually or over time, or some combination of the two. Because the projected pattern is known, how the sensor in the camera sees the pattern in the scene provides the depth information. For example, if the pattern is a series of stripes projected onto a ball, the stripes would deform and bend around the surface of the ball in a specific way.
If the ball moves closer to the emitter, the pattern would change too. Using the disparity between an expected image and the actual image viewed by the camera, distance from the camera can be calculated for every pixel.
Stereo depth cameras have two sensors, spaced a small distance apart. A stereo camera takes the two images from these two sensors and compares them. Since the distance between the sensors is known, these comparisons give depth information. Stereo cameras work in a similar way to how we use two eyes for depth perception. Our brains calculate the difference between each eye. Objects closer to us will appear to move significantly from eye to eye (or sensor to sensor), where an object in the far distance would appear to move very little.
Because stereo cameras use any visual features to measure depth, they will work well in most lighting conditions including outdoors. The addition of an infrared projector means that in low lighting conditions, the camera can still perceive depth details
Since the Intel realsense Depth camera D455 can send a depth frame as an output, we can retrieve the depth value from that depth frame. This process occurs in the Object recognition node.
Estimate real world position
After obtaining the position of the detected object in the pixel coordinate and the depth of that pixel position, we can use the knowledge of Camera Calibration and 3D Reconstruction. Then solve the equations to find the position in the real world coordinate from these values.
But in this case, we will use the pyrealsense2 library, which is a ready-made library to locate real-world coordinates. by defining position in pixel coordinates the depth of that pixel and other parameters of the camera model.
cd ..
colcon build --symlink-install
source ~/object_detection_ws/install/setup.bash
cd src/Software-Team/object_detection/scripts/
sudo chmod 777 *
Note
symlink-install is necessary.
Warning
must build in object_detection_ws/
Install library
cd ..
cd src/
pip install -r object_detection_requirements.txt
sudo apt-get install ros-(ROS version name)-cv-bridge
sudo apt-get install ros-(ROS version name)-vision-opencv
Verify library and object_detection package with basic node.
cdcd object_detection_ws/
ros2 run object_detection webcam_pub.py
##### open new terminal
ros2 run object_detection simple_detection.py
Use the Intel Depth Camera to send RGB frames and depth frames.
The ability to detect objects and the number of detected object types depends on the YOLOv5s6 model.
The maximum detection distance is about 5 meters.
You can try to use it with the following steps
Connect the Intel depth camera D435 to the computer and activate it via command
ros2 launch realsense2_camera rs_launch.py rgb_camera.profile:=640x480x30 depth_module.profile:=640x480x30
.. note::
The wrapper for Intel realsense cameras must be installed in ROS first. You can install it by following this link: https://docs.google.com/document/d/1IxUOK6chtMRrF6d4xHHuAmMR7w3yuLYyA5rUxMGGZgI
Open new terminal and cd to workspace director.
cdcd object_detection_ws/
Run the Object recognition node.
ros2 run object_detection object_detection_node.py
Open a new terminal and run the Estimate coordinate node.
ros2 run object_detection estimate_coordinate_rs2.py
Open a new terminal and call a service to start detecting objects.
ros2 service call /Object_Recognition/enable std_srvs/srv/Empty
Note
You can change the detection target by editing the self.target variable in the object_detection_node.py file.
The target name of the self.target variable must match the name of the result model YOLOv5 detects.
This is the main function of the Object Recognition node. It works only when enabled through the server. Inside the function, the image frame of each frame is imported into the YOLOv5 model, and the result is displayed as a whole image with a bounding box. and result data as a dataframe, and there will be conditions for detection.If the above conditions are met the function will pass the pixel coordinate position and the depth of that pixel to the Estimate coordinate node to find the in real world coordinate of the detected object.
Throughout the operation of this function, the operating status of the system is updated at all times.
This is a function for manipulating a dataframe of outputs from model YOLOv5. It adds position column and color column to the dataframe and then only selects the outputs based on the specified target.
Parameters:
df: The result of object detection of model YOLOv5 in the form of a dataframe.
From the experiment it was found that The maximum distance that model YOLOv5 can detect is about 5 meters. If the distance is exceeded it will make it difficult to detect objects.
Object detection precision.
From the experiment it was found that in object detection The same object can produce different detection results. Depends on the detection angle.
Material of object.
From the experiment it was found that transparent objects It may be difficult to estimate the distance between the subject and the camera.
In this unit testing detection performance including the accuracy of the detected location have not been tested.
The service that has been made can only be used in object detection capabilities. But if combined with other abilities, there will be problems. It is expected that there was a problem while building the package (CMakeLists.txt).
Futer Plan
Algorithm
The working process and internal functions are not as good as they should be. It can be developed to be more systematic and more optimized.
Training
It is possible to train models from custom data sets to increase the efficiency of detecting objects of interest. You can use Roboflow to help manage trains.
Because at present, only one pixel is used to detect the color of the object, which may cause color detection to be inaccurate. So we have to develop such detection. Clustering of color detection may be performed instead.
Pose estimate (position + orientation)
We can find the Pose of the object being detected. In order to pick up objects better. It may use the position in the real world coordinates obtained to estimate the next Pose or may use the pointcloud to estimate.